Технология выявления объектов и фактов с использованием синтактико-семантического анализа текста доказала свою эффективность и востребованность на рынке анализа текстовой информации, демонстрируя наивысшие показатели точности и полноты.
Однако, одной из проблем, с которой сталкиваются подобные системы, является сравнительно большая ресурсоемкость и низкая скорость обработки текста для выявления целевых объектов и фактов. К тому же для настройки на определенный набор фактов требуется анализ всего объема текстовых данных. При изменении целевого набора фактов требуется повторный анализ всего массива. Эта проблема является критичной для больших текстовых коллекций, когда время одного «прогона» может измеряться неделями. Для поиска конкретного факта необходимо предварительно произвести полный синтактико-семантический разбор коллекции текстов, найти и извлечь все факты, сохранить их в специализированной (фактографической) БД и уже в ней произвести поиск интересующего пользователя факта.
Наша система работает иначе. На первом этапе производится индексирование текстов, почти аналогичное таковому в «обычных» полнотекстовых поисковых системах, с одним отличием – в процессе индексирования производится также выявление упоминаний объектов и разрешение анафорических связей. Это сравнительно «быстрые» операции и такой дополнительный анализ практически не сказывается на скорости индексирования. Указанная разметка сохраняется в полнотекстовом индексе.
На втором этапе искомый факт (семантическое описание факта) трансформируется в запрос к поисковой машине, использующий как контекстные ограничения на слова, так и на семантическую разметку. В результате отработки данного запроса поисковая машина выдает набор фрагментов (предположительно содержащих искомый факт).
На третьем этапе производится полный синтактико-семантический анализ отобранных фрагментов, также с учетом семантической разметки и выявленных анафорических связей для точной идентификации всех упоминаний искомого факта.
Иллюстрирующий пример – поиск фактов о купле-продаже компаний.
Семантический шаблон описания данного факта (на примере системы RCO Fact Extractor) включает сведения об участии двух сторон и товара:
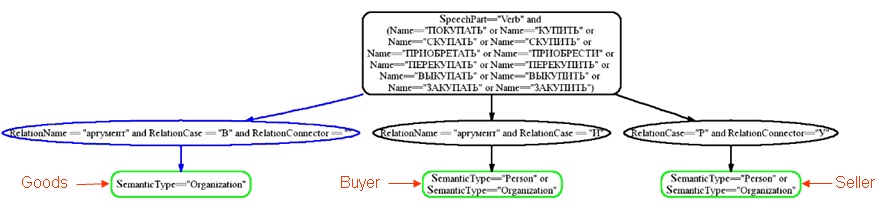
Переводим шаблон в поисковый запрос. Пример получившегося запроса (на примере системы RCO Zoom), с учетом семантической разметки:
ctx( obj(‘Перс:’ | ‘Орг:’) [5] (покупать | купить | скупать | скупить | приобретать | приобрести | перекупать | перекупить | выкупать | выкупить | закупать | закупить) [5] obj(‘Перс:’ | ‘Орг:’))
В данном запросе указано, что два объекта типа «Персона» или «Организация» находятся слева и справа на расстоянии не более 5 слов от перечисленных глаголов.
Этому запросу соответствуют следующие найденные фрагменты (на тестовой коллекции):
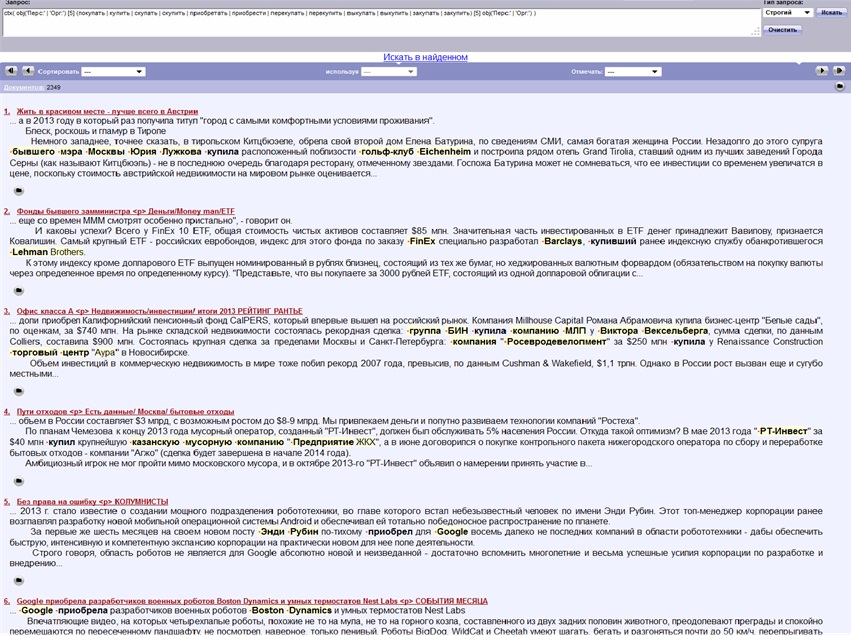
Далее система производит полный синтактико-семантический анализ найденных фрагментов и поиск интересующего факта. В процессе извлечения фактов осуществляется поиск подграфов графа синтактико-семантического разбора текста изоморфных шаблонам описания фактов.
Извлеченные факты (в первых четырех фрагментах):
| # | Фрагмент | Роли участников факта |
| 1 | Супруга бывшего мэра Москвы Юрия Лужкова купила расположенный поблизости гольф-клуб Eichenheim | Goods = ГОЛЬФ-КЛУБ EICHENHEIMBuyer = СУПРУГА ЛУЖКОВА ЮРИЯ МИХАЙЛОВИЧА |
| 2 | …Barclays, купивший ранее индексную службу обанкротившегося Lehman Brothers | Goods = ИНДЕКСНАЯ СЛУЖБА LEHMAN BROTHERSBuyer = BARCLAYS |
| 3 | Группа БИН купила компанию МЛП у Виктора Вексельберга | Goods = МЛПBuyer = БИНSeller = ВЕКСЕЛЬБЕРГ ВИКТОР ФЕЛИКСОВИЧ |
| 4 | …компания “Росевродевелопмент” за $250 млн купила у Renaissance Construction торговый центр “Аура” в Новосибирске. | Goods = ТОРГОВЫЙ ЦЕНТР “АУРА”Buyer = РОСЕВРОДЕВЕЛОПМЕНТSeller = RENAISSANCE CONSTRUCTION~Money = $250 МЛН~Place = НОВОСИБИРСК |
| 5 | В мае 2013 года “РТ-Инвест” за $40 млн купил крупнейшую казанскую мусорную компанию “Предприятие ЖКХ” | Goods = МУСОРНАЯ КОМПАНИЯ “ПРЕДПРИЯТИЕ ЖКХ”Buyer = РТ-ИНВЕСТ~Money = $40 МЛН~Time = В МАЕ 2013 ГОДА |
| … | … | … |
Таким образом, поставленная задача поиск фактов в Big Data, решается с максимальной полнотой и точностью. Полнота обеспечивается за счет использования поисковой машины для быстрого отбора фрагментов- кандидатов, а точность – за счет полного синтактико-семантического разбора найденных на первом этапе фрагментов.
В данном решении используются следующие продукты RCO: